Steps towards Crafting An Enhanced Search Experience

A software developer with a passion for bringing ideas to life.
These weeks have been a fusion of research, analysis, and design brainstorming, propelling the pursuit of a more user-friendly experience. So, gear up as we embark on this virtual expedition, exploring the fascinating progress I've made in revamping search functionality.
Exploring the Research Path:
Research is like a compass guiding innovation, and I eagerly jumped into studying different ways people make search work, some major inspirations were from the big players like Tailwind CSS, Bootstrap, Laravel and many more. Most of these had search implemented by Algolia, and the most obvious part that stood out was that the search was easily accessible everywhere thanks to their modal UI.
Tailwind's Search UI
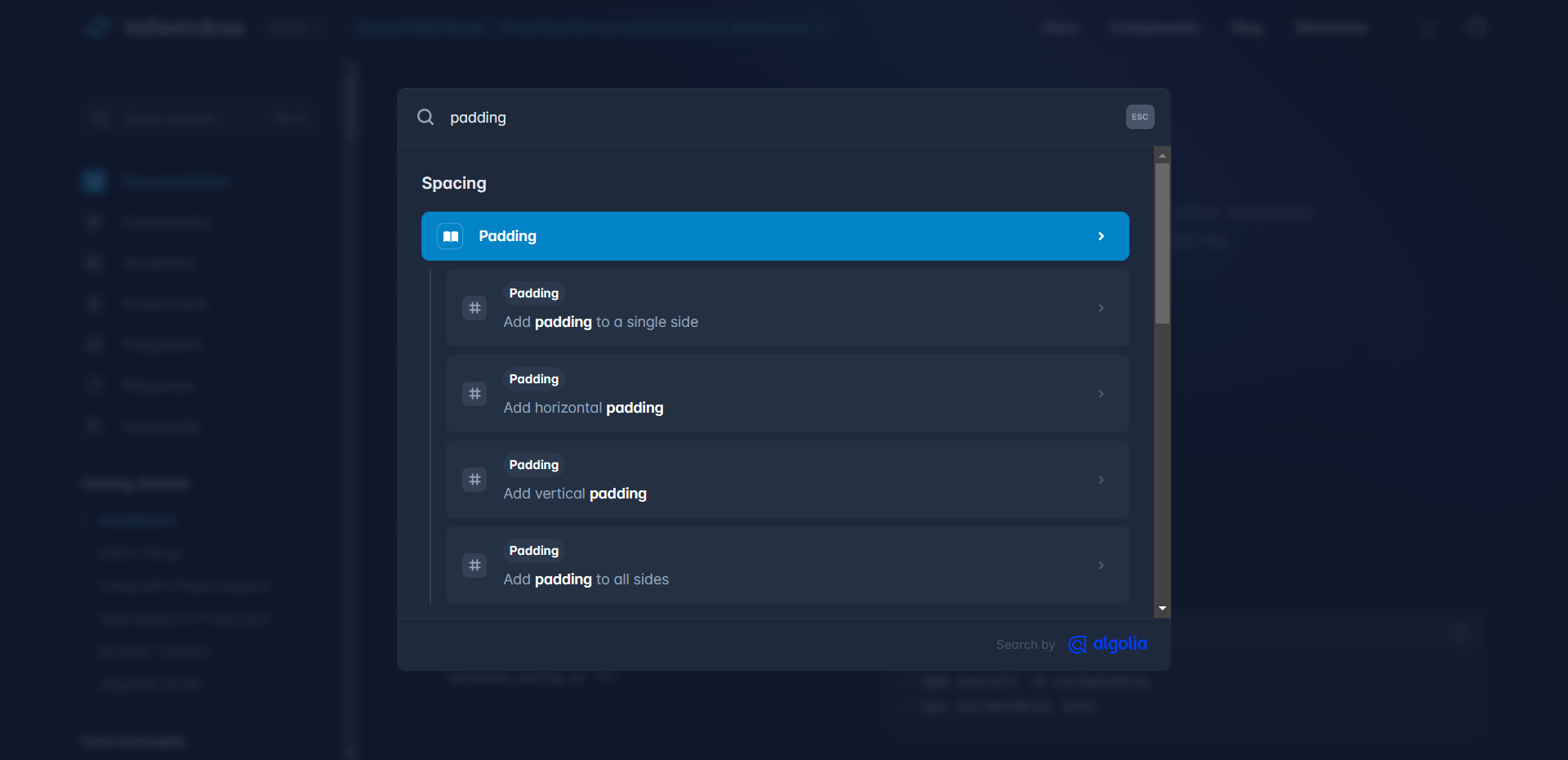
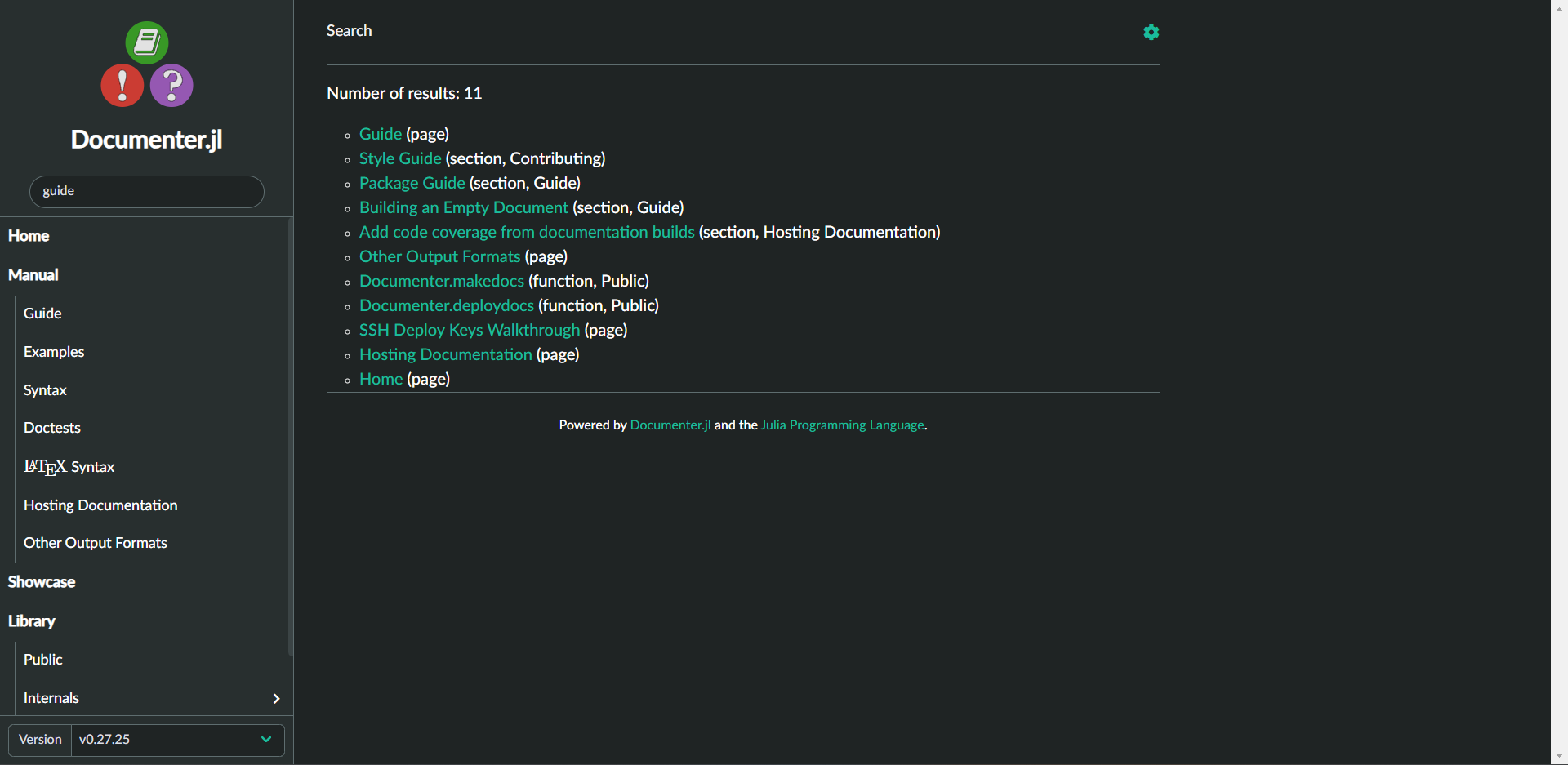
While it was clear as day that there was a need for a better search in Documenter, the current is a bit too simplistic. One other major flaw was that the search was only accessible through a single Search page which the user had to visit every time they had to search something.
Currently generated UI
Generating Issues:
Well, after the weekly meeting with my mentor, we decided to open up two issues as the first step in the upcoming process. One for the UI improvements and another for changing the search engine.
The GitHub issue for UI: Updating the search UI
The GitHub issue for Changing Search Engine: Changing the search engine
Code Action:
Now, for the truly fascinating part – coding! As much as I enjoyed immersing myself in research, there's an unmatched thrill in turning ideas into lines of code.

Speaking of which, let me share a glimpse of what's been cooking in the coding kitchen. Inspired by the quest for a speedier search experience, I began crafting a preliminary script for pre-building the search index. Imagine this as a way to give our search engine a head start – much like a car's engine warming up before hitting the road. This script is destined to play a pivotal role in our CI/CD (Continuous Integration and Continuous Deployment) process. By automating the index creation in this way, we're not only boosting search speed but also ensuring a more consistent and reliable experience for all users.
// data.json
[
{
"location": "stdlib/CRC32c.html#CRC32c",
"page": "CRC32c",
"title": "CRC32c",
"text": "",
"category": "section"
},
{
"location": "stdlib/CRC32c.html",
"page": "CRC32c",
"title": "CRC32c",
"text": "Standard library module for computing the CRC-32c checksum.",
"category": "page"
}
]
// Rudimentary script for index generation
let fs = require('fs')
let gz = require('zlib')
let data = require('./data.json')
const Minisearch = require('./minisearch.js')
data = data.map((x, key) => {
x['id'] = key
return x
})
const stopWords = new Set([
'a',
'able',
'about',
'across',
'after',
'almost',
'also',
'am',
'among',
'an',
'and',
'are',
'as',
'at',
'be',
'because',
'been',
'but',
'by',
'can',
'cannot',
'could',
'dear',
'did',
'does',
'either',
'ever',
'every',
'from',
'got',
'had',
'has',
'have',
'he',
'her',
'hers',
'him',
'his',
'how',
'however',
'i',
'if',
'into',
'it',
'its',
'just',
'least',
'like',
'likely',
'may',
'me',
'might',
'most',
'must',
'my',
'neither',
'no',
'nor',
'not',
'of',
'off',
'often',
'on',
'or',
'other',
'our',
'own',
'rather',
'said',
'say',
'says',
'she',
'should',
'since',
'so',
'some',
'than',
'that',
'the',
'their',
'them',
'then',
'there',
'these',
'they',
'this',
'tis',
'to',
'too',
'twas',
'us',
'wants',
'was',
'we',
'were',
'what',
'when',
'who',
'whom',
'why',
'will',
'would',
'yet',
'you',
'your',
])
let search_index = new Minisearch({
fields: ['title', 'text'], // fields to index for full-text search
storeFields: [
'location',
'title',
'text',
'category'
], // fields to return in results
tokenize: (string, _fieldName) => string.split(/[\s\-\.]+/),
processTerm: (term, _fieldName) => {
let word = stopWords.has(term) ? null : term.toLowerCase()
if (word) {
word = word.replace(/^[^a-zA-Z0-9@!]+/, '')
.replace(/[^a-zA-Z0-9@!]+$/, '')
}
return word ?? null
},
searchOptions: {
boost: { title: 100 },
fuzzy: 0.2,
tokenize: (string, _fieldName) => string.split(/[\s\-\.]+/),
},
})
search_index.addAll(data)
// To write a gzip json file
// To read a gzip file on client side use pako
// gz.gzip(Buffer.from(JSON.stringify(search_index)), (_, result) => {
// fs.writeFileSync('../assets/search_index.json.gz', result)
// })
fs.writeFileSync('../assets/search_index.json', JSON.stringify(search_index))
So, while the coding journey is just beginning, the potential impact is already looking promising. Stay tuned for more technical insights and the adventures that await as I transform lines of code into meaningful enhancements for all.
Next time, I will be going through the actual internal workings of the searching logic with the semi-improved UI for the current search and what the mid-term evals are in GSoC. And for those curious minds who've been inquiring about my GSoC proposal, I've got a treat for you! I will also be linking my proposal, where the initial seeds of this exciting journey were sown. Stay tuned for more updates as I continue to shape the future of Julia's search functionality. Until next time, keep coding and dreaming big!
If you're interested in following my progress or connecting with me, please feel free to reach out!
Github: Hetarth02
LinkedIn: Hetarth Shah
Website: Portfolio
Thank you for joining me on this journey, and look forward to more updates as I continue to contribute to the Julia community during GSoC.
Credits:
Cover Image by Kevin Granger




