Transitioning from Lunr.js to Minisearch.js

A software developer with a passion for bringing ideas to life.
As I embarked on weeks five and six of my Google Summer of Code (GSoC) project, a pivotal shift took place in client-side searching. To optimize the initial load times, I transitioned from using Lunr.js to Minisearch.js. This change brought about a host of improvements and refinements that made a more efficient search functionality. In this blog post, I'll delve into the intricacies of this transition and explore key concepts of this transition.
Current Implementation:
lunr.tokenizer.separator = /[\s\-\.]+/;
lunr.trimmer = function (token) {
return token.update(function (s) {
return s.replace(/^[^a-zA-Z0-9@!]+/, "").replace(/[^a-zA-Z0-9@!]+$/, "");
});
};
lunr.Pipeline.registerFunction(lunr.stopWordFilter, "juliaStopWordFilter");
lunr.Pipeline.registerFunction(lunr.trimmer, "juliaTrimmer");
var index = lunr(function () {
this.ref("location");
this.field("title", { boost: 100 });
this.field("text");
documenterSearchIndex["docs"].forEach(function (e) {
this.add(e);
}, this);
});
tokens.forEach(function (t) {
q.term(t.toString(), {
fields: ["title"],
boost: 100,
usePipeline: true,
editDistance: 0,
wildcard: lunr.Query.wildcard.NONE,
});
q.term(t.toString(), {
fields: ["title"],
boost: 10,
usePipeline: true,
editDistance: 2,
wildcard: lunr.Query.wildcard.NONE,
});
q.term(t.toString(), {
fields: ["text"],
boost: 1,
usePipeline: true,
editDistance: 0,
wildcard: lunr.Query.wildcard.NONE,
});
});
As you can see, we currently have many moving components in the search logic. There is a tokenizer, a trimmer function, we are boosting some fields and an editDistance parameter which is used during the search. We will learn what each of these is step by step.
Tokenization: The Foundation of Search
lunr.tokenizer.separator = /[\s\-\.]+/;
The process of tokenization involves breaking down the search input into individual tokens or words. This step is crucial as it lays the groundwork for the search engine to efficiently match the tokens against the indexed documents. Each token is subsequently treated as a unique identifier that allows for accurate and targeted search results. Here, we have regex which tokenizes the word using white-space or . because there are results such as Documenter.Anchors.add! which would not trigger anything if we do not tokenize it properly.
Trimmer Function: Polishing the Search Input
One of the challenges you encounter is dealing with special characters and unwanted characters that might hinder the search process. To address this, a trimmer function that sanitizes the search input is used. This function identifies and removes extraneous characters, ensuring that the search query remains clean and focused. This significantly contributes to the accuracy of search results. However, there might be certain characters that are useful to us and hence we again make use of regex to not remove those characters.
// custom trimmer that doesn't strip @ and !
lunr.trimmer = function (token) {
return token.update(function (s) {
return s.replace(/^[^a-zA-Z0-9@!]+/, "").replace(/[^a-zA-Z0-9@!]+$/, "");
});
};
Stopwords: Filtering out the Noise
Stopwords are common words such as and, the, is, etc., that hold little semantic value and can be safely excluded from search queries. By identifying and filtering out stopwords, the search engine can allocate more attention to meaningful keywords and ultimately improve the relevance of the search results. This is particularly important when aiming for precision in search queries.
// List of stop words used
[ "a","able","about","across","after","almost","also","am","among","an","and","are","as","at","be","because","been","but","by","can","cannot","could","dear","did","does","either","ever","every","from","got","had","has","have","he","her","hers","him","his","how","however","i","if","into","it","its","just","least","like","likely","may","me","might","most","must","my","neither","no","nor","not","of","off","often","on","or","other","our","own","rather","said","say","says","she","should","since","so","some","than","that","the","their","them","then","there","these","they","this","tis","to","too","twas","us","wants","was","we","were","what","when","who","whom","why","will","would","yet","you","your" ]
Field Boosting: Spotlighting Priority Fields
In scenarios where certain fields within a document hold higher importance, field boosting comes into play. This technique assigns higher relevance scores to specific fields, effectively prioritizing them in the search results. For instance, if you're searching for products, boosting the "product name" field might yield more accurate outcomes than boosting other less relevant fields.
var index = lunr(function () {
this.ref("location");
// Boost score when title matches
this.field("title", { boost: 100 });
this.field("text");
documenterSearchIndex["docs"].forEach(function (e) {
this.add(e);
}, this);
});
Fuzzy Searching: Embracing Variability
Fuzzy searching is an indispensable feature that accounts for slight variations and typos in search queries. Edit distance, a metric used to measure the similarity between two strings, is a fundamental component of fuzzy searching. When users inadvertently mistype a word or opt for a slightly different variant, fuzzy searching leverages edit distance to identify potential matches. This ensures that users aren't penalized for minor errors such as typos or when a cat walks over their keyboard and are still presented with relevant results.
Transitioning to MinisearchJs
Well, the above might seem daunting but minisearch is very flexible and is extremely developer friendly. Below is the minisearch implementation.
let index = new minisearch({
fields: ["title", "text"], // fields to index for full-text search
storeFields: ["location", "title", "text", "category", "page"], // fields to return with search results
processTerm: (term) => {
let word = stopWords.has(term) ? null : term;
if (word) {
// custom trimmer that doesn't strip @ and !, which are used in julia macro and function names
word = word
.replace(/^[^a-zA-Z0-9@!]+/, "")
.replace(/[^a-zA-Z0-9@!]+$/, "");
}
return word ?? null;
},
// add . as a separator, because otherwise "title": "Documenter.Anchors.add!", would not find anything if searching for "add!", only for the entire qualification
tokenize: (string) => string.split(/[\s\-\.]+/),
// options which will be applied during the search
searchOptions: {
boost: { title: 100 },
fuzzy: 2,
processTerm: (term) => {
let word = stopWords.has(term) ? null : term;
if (word) {
word = word
.replace(/^[^a-zA-Z0-9@!]+/, "")
.replace(/[^a-zA-Z0-9@!]+$/, "");
}
return word ?? null;
},
tokenize: (string) => string.split(/[\s\-\.]+/),
},
});
Was the switch worth it?
In one word, Yes! It improved cold start times by a certain magnitude but it mainly reduced the size of the index by 16%.
Implementation of Design Mockups and Static Build:
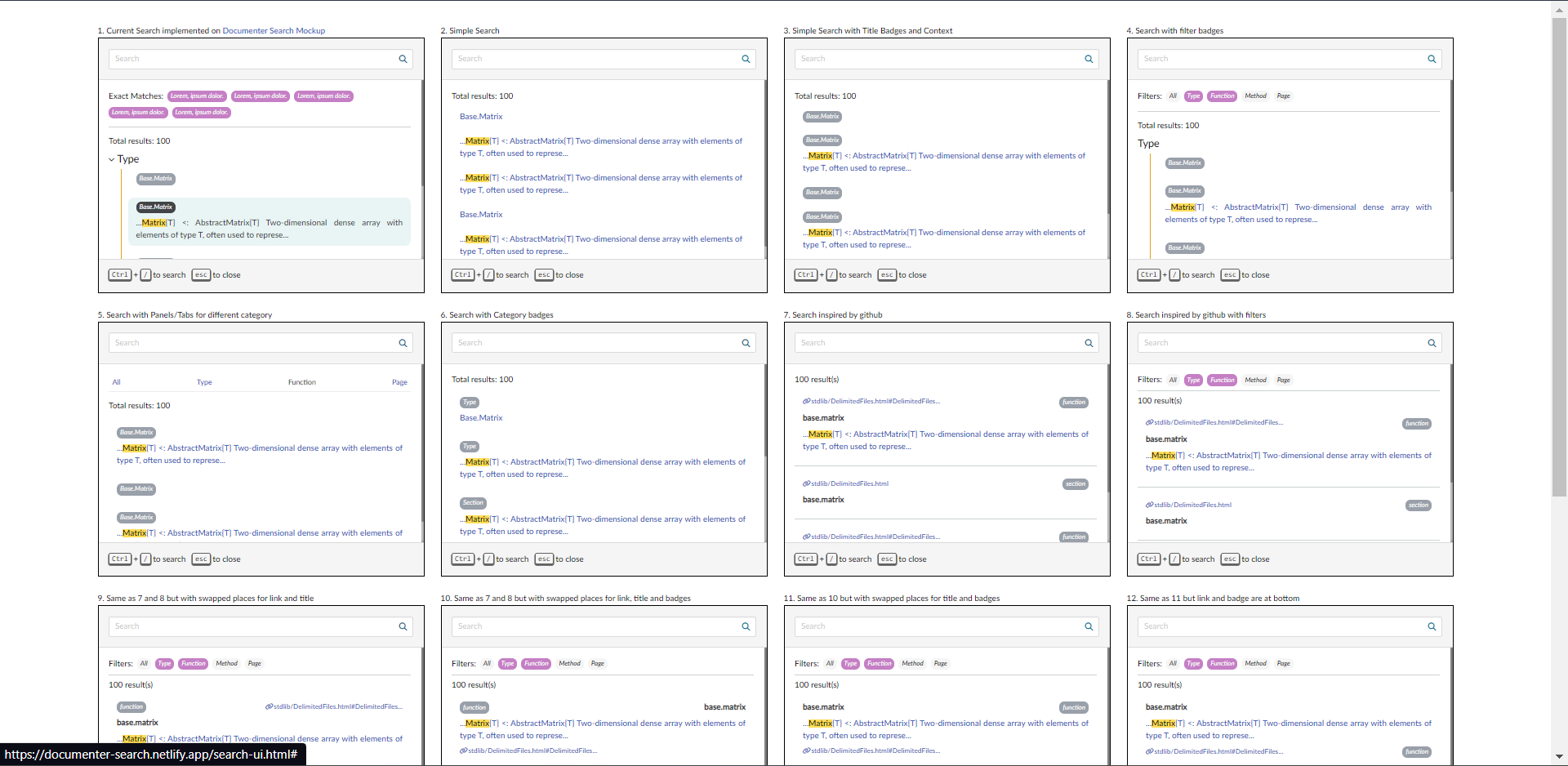
Leveraging insights from prior research on search UIs, I crafted interactive and user-friendly interfaces. These designs were aimed at enhancing the visual and functional aspects of the search modal. This involved ensuring seamless navigation, clean typography, and optimal placement of UI elements. What followed was the creation of a static build housing an impressive array of ten or more UI variations for the search modal. This diverse set of UIs allows for a comprehensive exploration of different visual and interactive possibilities.
If someone wants to test out the different options then head here, Mock Search UIs
⚡An Unexpected Development:
With the JuliaCon 2023 coming up, my mentor asked if I could improve the current search listing with something that can be presentable enough. Well, we quickly set up a meeting to discuss how we could improve the current listing in a way that is fast enough and doesn't require much time. In the end, we decided to go with keeping the listing as it is because integrating a full-blown modal UI would require time and iterations based on feedback. Hence, we agreed to update the results using the new UI as a reference. And since I already had all the required data at my hands coming from minisearch it was just a matter of updating the DOM structure and some CSS magic🪄. I quickly put together the elements and this was the result.


📜Mid-Term Evals:
With the search engine changed and the mockups built, I was pretty much ready for the mid-term evaluation. This is an optional evaluation for both the mentors and contributors where each leaves feedback for the other and answers some basic questions. But, if a mentor fails you in the evals you won't be able to continue. This fact had me feeling nervous, but since I was ahead of the tasks I passed with flying colours.
📎Sharing My GSoC Proposal:
For those who are curious to delve deeper into the foundations of my GSoC project and explore the roadmap that led to all this, I invite you to take a look at my GSoC proposal. It outlines the initial concepts, goals, and strategies that have guided these weeks of progress. Feel free to explore the proposal here📝. Your interest in the journey is greatly appreciated, and I'm excited to share this transformative process with you.
If you're interested in following my progress or connecting with me, please feel free to reach out!
Github: Hetarth02
LinkedIn: Hetarth Shah
Website: Portfolio
Thank you for joining me on this journey, and look forward to more updates as I continue to contribute to the Julia community during GSoC.
Credits:
Cover Image from Minisearch Repo.




